With complicated structure in a supply chain, it has been a challenge for executives to see and understand the associated changes and movements in a supply chain. Examples are raw materials, inventory, products, marketing campaigns, promotions, and other supply chain activities.
As brands and products proliferate, are spun off, and re-consolidated, supply chain companies find themselves struggling to understand what they have, what they need, and where they’re going. Doing so requires a tremendous amount of data, drawn from both external sources (suppliers, partners, customers) and internal ones (marketers, production managers, supply chain groups). The ability to see all of the data surrounding a brand at a glance is a tall order, one only made harder by the proliferation of systems and processes designed to support it. Before companies can profit from efficiencies of scale, they need to consolidate these systems. This is an area where business intelligence (BI) can help them.
However, melding disparate data sources through business intelligence turns out to be a disaster, when companies are using multiple technologies under one roof. These technologies could be from Microsoft, Oracle, SAP, IBM, Teradata, and others. People are struggling before BI implementation, and people are struggling even more after it. As a result, instead of placing information in the hands of the managers who needed it, they are now locked inside those data and technologies, where they could barely get to the real BI they desperately need. On the other hand, IT departments are struggling with questions like: “how many people I needed to build reports”, “how long it is going to build reports”, and “what those reports should look like”.
To meet the challenges of data and technologies, a possible solution is QlikView or Qlik Sense from Qlik. Compared to other BI vendors, the most unique feature of QlikView / Qlik Sense is that people don’t have to think about the joins of tables; people don’t even have to think about which tables to pull out of their ERP. The appliance just bolts onto the side and sucks the whole thing out. People, or even non-IT people, can spent a week extracting the relevant data tables from the central data warehouse, then loading them into QlikView / Qlik Sense as individual data sets — one for sales, one for materials management, and so forth. And, suddenly, they can gaze across a total landscape of its supply chain before drilling down by product or brand or segment or market — or any combination it liked.
With QlikView / Qlik Sense, companies can train or hire a handful of savvy managers who in time became the trainers for their respective divisions. When the need arises for a report, they’ll point you to an existing report or enhance it or build a new one if need be, if everyone agrees it’s the right thing to do. People are taking reports into their own hands and customizing them to suit their needs.
In addition to this special feature, people can also implement their supply chain management BI by using one of the following templates in Qlik Demo site:
- Executive Insights
- Production Insights
- Forecasting and Planning
- Sourcing and Supplier
- Regulatory Compliance
- IT Management
- Warehousing and Distribution
- Transportation and Logistics
- Merchandise Management
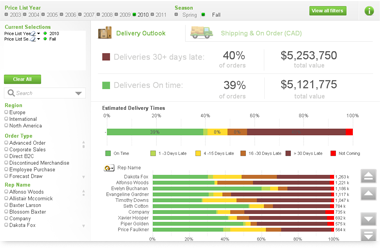
In addition, people can find other supply chain solutions provided by Qlik vendors at the Qlik Market. A screenshot of the Order and Inventory Management Dashboard is enclosed below. You can go to its interactive demo site here.

In summary, supply chain management is implemented in QlikView / Qlik Sense as applications or reports in all areas of the supply chain management, which can come from one of a reports template Qlik provides, custom made to match what you have today, or created by one of its vendors. The applications and reports do not need specialized IT departments to create and can be created by your very own people in the field.
References:




































![How to Become a Google Plus Wizard [INFOGRAPHIC]](http://supplychaininstitute.com/wp_sci/wp-content/uploads/2014/09/263501645_80_80.jpg)