Some of us have been hearing more about the data lake, especially during the last six months. There are those that tell us the data lake is just a reincarnation of the data warehouse—in the spirit of “been there, done that.” Others have focused on how much better this “shiny, new” data lake is, while others are standing on the shoreline screaming, “Don’t go in! It’s not a lake—it’s a swamp!”
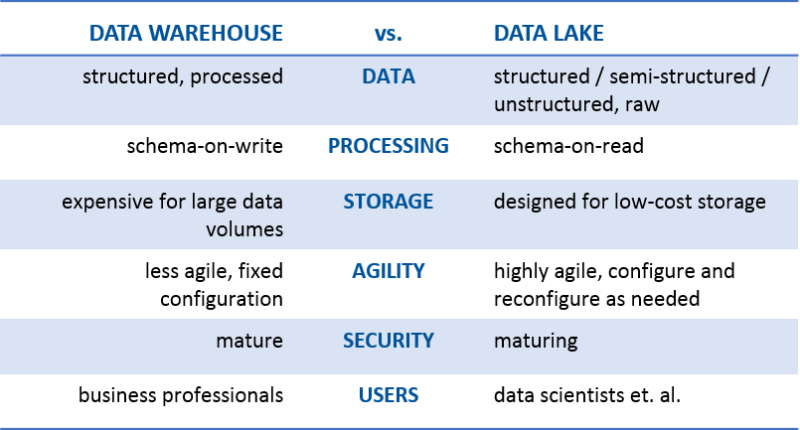
All kidding aside, the commonality I see between the two is that they are both data storage repositories. That’s it. But I’m getting ahead of myself. Let’s first define data lake to make sure we’re all on the same page. James Dixon, the founder and CTO of Pentaho, has been credited with coming up with the term. This is how he describes a data lake:
“If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
And earlier this year, my colleague, Anne Buff, and I participated in an online debate about the data lake. My rally cry was #GOdatalakeGO, while Anne insisted on #NOdatalakeNO. Here’s the definition we used during our debate:
“A data lake is a storage repository that holds a vast amount of raw data in its native format, including structured, semi-structured, and unstructured data. The data structure and requirements are not defined until the data is needed.”
What do you think about this topic? Share your opinions below and subscribe us to get updates in your inbox.