Architecting a Machine Learning System for Risk
Online risk mitigation
At Airbnb, we want to build the world’s most trusted community. Guests trust Airbnb to connect them with world-class hosts for unique and memorable travel experiences. Airbnb hosts trust that guests will treat their home with the same care and respect that they would their own. The Airbnb review system helps users find community members who earn this trust through positive interactions with others, and the ecosystem as a whole prospers.
We can mitigate the potential for bad actors to carry out different types of attacks in different ways.
1) Product changes
Many risks can be mitigated through user-facing changes to the product that require additional verification from the user.
2) Anomaly detection
Scripted attacks are often associated with a noticeable increase in some measurable metric over a short period of time.
3) Simple heuristics or a machine learning model based on a number of different variables
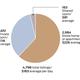
Fraudulent actors often exhibit repetitive patterns.
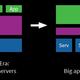
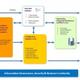
Machine Learning Architecture
Different risk vectors can require different architectures. For example, some risk vectors are not time critical, but require computationally intensive techniques to detect. An offline architecture is best suited for this kind of detection. For the purposes of this post, we are focusing on risks requiring realtime or near-realtime action. From a broad perspective, a machine-learning pipeline for these kinds of risk must balance two important goals:
1) The framework must be fast and robust.
That is, we should experience essentially zero downtime and the model scoring framework should provide instant feedback.
2) The framework must be agile.
Since fraud vectors constantly morph, new models and features must be tested and pushed into production quickly.
What do you think about this article? What have you learned from it? If you have any opinions, leave comments below or send us a message.