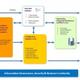
Hadoop and Data Warehouses
I see a lot of confusion when it comes to Hadoop and its role in a data warehouse solution. Hadoop should not be a replacement for a data warehouse, but rather should augment/complement a data warehouse. Hadoop and a data warehouse will often work together in a single information supply chain: Hadoop excels in handling raw, unstructured and complex data with vast programming flexibility; Data warehouses, on the other hand, manage structured data, integrating subject areas and providing interactive performance through BI tools.
There are three main use cases for Hadoop with a data warehouse, with the above picture an example of use case 3:
1. Archiving data warehouse data to Hadoop (move)
Hadoop as cold storage/Long Term Raw Data Archiving:
– So don’t need to buy bigger PDW or SAN or tape2. Exporting relational data to Hadoop (copy)
Hadoop as backup/DR, analysis, cloud use:
– Export conformed dimensions to compare incoming raw data with what is already in PDW
– Can use dimensions against older fact table
– Sending validated relational data to Hadoop
– Hadoop data to WASB and have that used by other tools/products (i.e. Cloud ML Studio)
– Incremental Hadoop load / report3. Importing Hadoop data into data warehouse (copy)
Hadoop as staging area:
– Great for real-time data, social networks, sensor data, log data, automated data, RFID data (ambient data)
– Where you can capture the data and only pass the relevant data to PDW
– Can do processing of the data as it sits in Hadoop (clean it, aggregate it, transform it)
– Some processing is better done on Hadoop instead of SSIS
– Way to keep staging data
– Long-term raw data archiving on cheap storage that is online all the time (instead of tape) – great if need to keep the data for legal reasons
– Others can do analysis on it and later pull it into data warehouse if find something useful
Thanks for reading this article. If you have any opinions, please leave a comment below or send us a message